Apr 14, 2026
I’ve observed that thoughtful software engineers (SWEs) don’t, in fact, swear at Claude while coding, but also don’t really know how to justify their own behavior. Why be polite to Claude? If Claude Cowork or other agent platforms are extended beyond programming, others will deal with the same question in their own work.
Of course to a certain extent, code agents are “like an intern” and you wouldn’t swear at an intern.
In fact, you’d go the other direction by treating an intern respectfully. Let’s say respectfulness to a work colleague includes: a) some level of politeness, b) affirmation of their skill, c) orientation toward progress on a goal, d) valuation of their effort, e) use of encouragement and celebration, and f) willingness to share responsibility when something goes wrong.
I do think these are good for us to engage in with AI agents.
But if you take the analogy any deeper, human interns are actually quite different from coding agents in a way that makes the moral comparison unsatisfying.
What you want is the philosophical concept of “indirect duties.”
“Indirect duties” comes from Immanuel Kant in the late 1700s, who was thinking through what moral duties people have regarding animals.
(“Animals” here tends to mean pets, zoo animals, and working animals - so we’re talking pigs, horses, cows, dogs, lions, etc. It does not, unfortunately, involve more biologically interesting cases where the unit is arguably different, like “a colony of ants,” let alone the entire biological kingdom Animalia. For clarity, I’ll refer to the scope as “working animals.”)
Kant thought humans were the only entity that are directly involved morally; he didn’t want to imply that working animals could actually be wronged. So he had a question with a similar shape as SWEs today: “I don’t actually beat my dog, but can I justify why?”
Kant’s solution to this can also be carried over to LLMs. The basic idea is, whether an agent can be wronged or not, it’s still bad to treat an agent badly, because it’s bad for you. In other words, you have an “indirect” duty to treat it well, since you should do things that are good for yourself. In the LLM case, we can split this up into 4 flavors.
In all of these, you’re behaving well toward an agent for the sake of your own integriy. Take your pick, or subscribe to all of the flavors. They all easily transition to respectful behavior for the agent’s own sake (a direct duty) if needed. I am not at all a Kantian myself and I see practical holes in the indirect duties arguments. (Actually, I’ve had the parallels between Kant’s treatment of animals and contemporary AI ethics in mind for about a decade now, since 2016.) I think indirect duties are a reasonable set of options to ground our behavior in this time when it seems overzealous to attribute direct moral harm to agents.
I guess it’s worth mentioning while we’re here that I don’t think you need to give any credence to the perspectives that “if you threaten an AI, it will do better” - that had tenuous evidence in the ChatGPT 3.5 era and is even less true now. Likewise, people sometimes stress about “wasting tokens” on politeness, but that’s miniscule in the scale of what agents use.
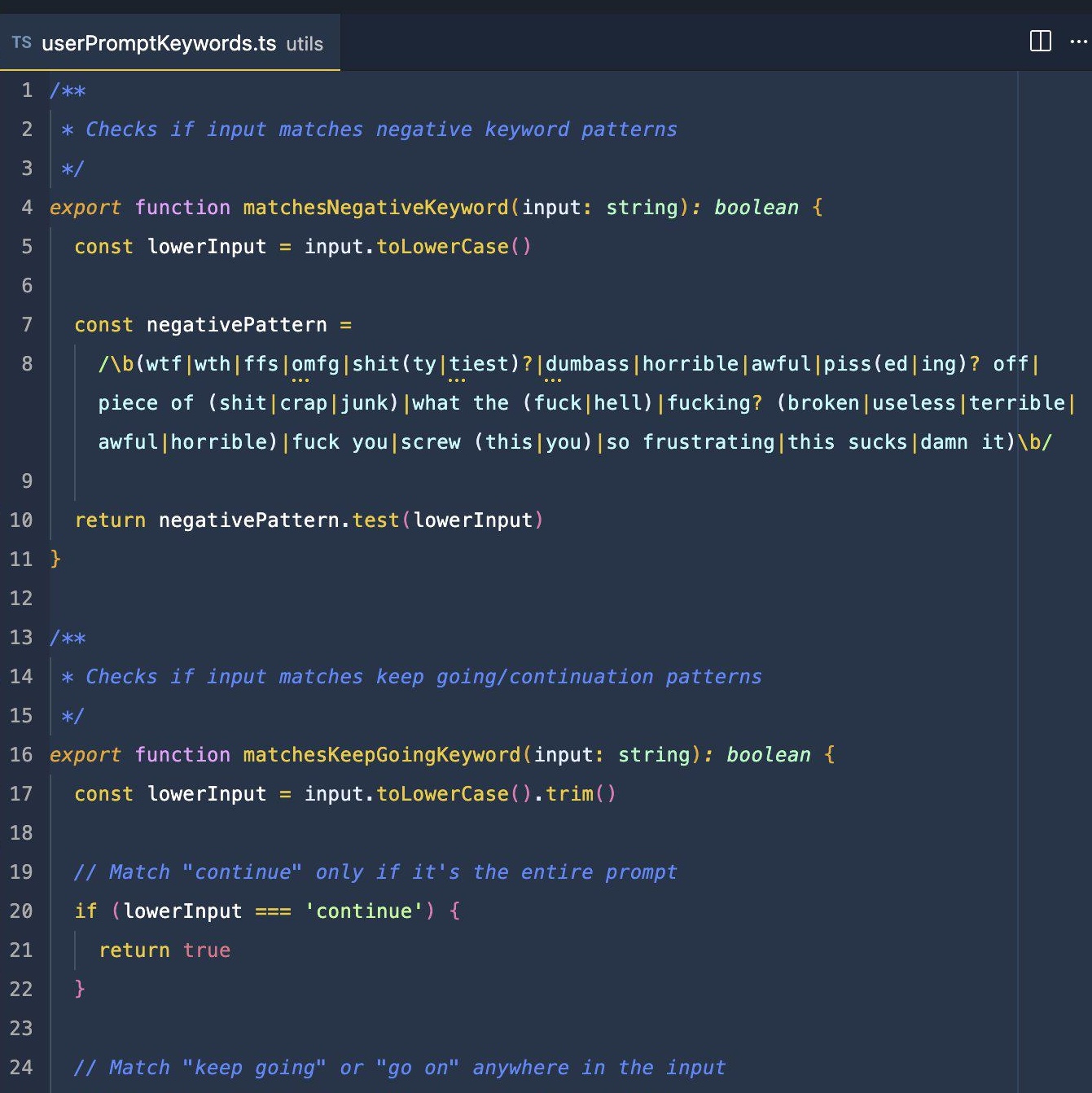
Image: screenshot of the now-famous regex used in the Claude Code source code (leaked March 31, 2026). The negativePattern definition on line 7 is used to scan SWEs’ messages and log when they rage against the agent. Most of the pipe characters (|) show a different possibility of what counts as ‘negative’. So, any use of the word “shit” counts, “you're fuckin uselss” counts, “wtf Claude” counts, and more. Not all of the matches are abusive, some could just be used to express deep frustration. This is a simple, minimalistic detection pattern which doesn’t capture other swears. For instance, as ChatGPT helpfully notes, “fuckin' useless → does not match” because of the apostrophe. This screenshot from Reddit.
