This webtext is guided by a single question: What identities do we make
available to people through the artificial intelligence (AI) agents we create?
This question speaks to issues of representation, interaction, and identity in
an emerging technological context. To answer it, a corpus of about 25 popular
YouTube videos created by underrepresented people about Apple's voice assistant
Siri are brought together together for the first time. Each video in this corpus
either reimagines Siri to be more like the creator (to be black, Mexican, gay,
lesbian, Muslim, Jewish, or Mormon), and/or critiques Siri for not understanding
certain people's accents and for subtly taking on dominant identities.
After an introductory video, I analyze the corpus videos in the form of two videos, each a little
less than 20 minutes long, in order to adequately draw in the YouTubers' literal voices
regarding AI and identity. In Part 1, "Reimagining Inclusive AI," my
focus is on what would be involved for Siri to take on a different identity,
especially since Siri isn't traditionally embodied. The YouTube
corpus imagines Siri adopting culturally specific knowledge, values, ways of
interacting, and commercial activity. These help reconceptualize how AI development
could proceed more inclusively. In Part 2,
"Critiquing Identity Erasure," my analysis turns to how the YouTube corpus
critiques today's Siri. This part finds that these YouTubers largely critique today's real Siri
as implicitly occupying dominant identity categories (straight, white,
nonreligious, and unaccented), because the current Siri hides its power,
cultivates possessiveness, and is misguided in portraying its actions as neutral.
These point to opportunities for critics to advocate "revising" Siri's
self-presentation. A conclusion video wraps up these themes and points to practical implications.
Overall, the project hopes to surface critiques and possibilities that,
because they've been presented humorously on YouTube, might otherwise go
undetected. At a larger level, this effort seeks to bring diverse representation and
equity to our AI imaginary itself.
[Download print version of this webtext TO BE INSERTED UPON ACCEPTANCE OF THE WEBTEXT - meant both as an
accessibility device and as a way to accommodate scholarly reading
practices, which often depend on being able to store something away for
future use.]
Note on Format
Each section of video analysis has expandable transcript and commentary.
This text plays three functions relative to the videos:
Transcript. Transcriptions are notorious places for subtle linguistic
oppression to take place (Lueck, 2017, "Discussion" section; McFarlane &
Snell, 2017), so keeping the video primary (and making the transcripts expandable) is one way to
preserve the complex and ambiguous aspects of the YouTube parody videos. In each
transcript, “[onscreen subtitles]” indicates that a YouTuber provided their own
subtitles—even with variant spellings, punctuation, and unintuitive
translations into English, these self-selected subtitles are preferred, since
they show the creator(s) navigating accent/language and that's often what's at
issue with Siri. Hyphens in the transcript indicate a new excerpt; line breaks
and parenthetical indicators show who's speaking, when relevant.
Scholarly Connections. In each section of a video's transcript, certain phrases are
linked to additional commentary, similar to footnotes. In part, this commentary
makes scholarly connections that would be unwieldy in video form. For instance,
the Part 1 video simply notes that one of the values of the Black Siris is to “refuse to answer stupid
questions,” with examples from the parodies. The linked commentary, in turn, does extended
textual work to connect scholarship on cultural interactional patterns with
communicative resistance in digital spaces. Reserving most scholarly connections
for text leverages videos as accessible for a wider audience, while maintaining the
"inside baseball" for more dedicated readers. This intentionally reverses the
insider-outsider dynamic of scholarship.
Nuance. Finally, the text commentary also allows for reflective,
nuanced, and personal responses to delicate elements of the video analysis. Some
of the YouTube videos being analyzed are crude and unpalatable identity-based
parodies. The video analysis keeps an eye on the research story and navigates
viewers through safe waters, and the text can then disturb and qualify certain
claims. See, for instance, one of the longer notes in the Part 1 conclusion, on
parodies that are “downright cringe-worthy.”
Embedded in these purposes is an intended flow or “reading path” of some people
encountering the videos on YouTube itself, with only a limited number starting
from the confines of the academic article. Similarly, students can reasonably watch the
whole project for homework in a class (on, say, digital storytelling or language
and identity) without necessarily reading all of the commentary.
Introduction
Introduction
In late 2011, Apple announced that a voice assistant called Siri would come with the iPhone 4S. Siri could do things like take dictation for text messages, set timers, and answer questions about the weather, stocks, and nearby restaurants.
-[Apple presenter] “What is the weather like today?” [Siri] “Here’s the forecast for today.” “It is that easy.” [applause] (Apple Special Event 2011)
-“The iPhone 4S is instead creating confusion … Is it a nice day?” [Newscaster] “Let’s see what it says.” [Siri] “I don’t know what you mean by, ‘Is it NSD to says.’” (iPhone has problems with Scottish accents)
-[Siri] “I don’t know what you mean by ‘walk.’ Which email address for, work or home?” “Work.” “Kamei, I don’t understand, ‘wall.’ Which email address for, work or home?” “Work.” (Siri vs Japanese)
Some videos began to play with this idea by dramatizing how difficult it was for them to interact with Siri. For instance, in a funny mashup of the “Shit ____ People Say” meme, the video “Stuff Hyderabadi Moms Say to Siri” shows how age, gender, status, language, and technical familiarity intersect to make a frustrating experience for an imagined Indian mother and her daughter:
-[on-screen subtitles] “shri is not understanding anything. SHRI! Hello?” [Siri] “Hello.” [on-screen subtitles] “Look, now she understands. Call my friend Bilqees, Shri.” “I can’t search near businesses, sorry about that.” (Stuff Hyderabadi Moms)
Other videos played with Siri in a different way. Instead of dramatizing challenges with the current Siri, they reimagined Siri to be more like them.
-“So I went in there and customized it a little bit, to make it more personal for me. So I present to you, Black Siri.” (Black Siri)
-“Well, I’ve got an app that will help you choose the right. Mormon Siri.” (Mormon Siri)
-“Apple CEO Tim Cook has come out, and to celebrate, we’ve made an exciting new update to every iPhone. Say hello to iGay.” (iGay iPhone)
These reimaginations go beyond accent or national origin to examine how Siri could inhabit other identities like race, religion, and sexual orientation.
Hi, I'm Will Penman. This project brings these videos together for the first time to see what we can learn from them.
Commentary and points of connection for "Introduction"
Siri's abilities have expanded over time. Since 2016, Siri has been able to
serve as an interface for other apps, and this has been extended to allow custom
commands and bundled actions (Tillman, 2019). Users can now correct Siri's
pronunciation of individual words (Mundy, 2019), and Siri personalizes
recommendations based on a users' habits, e.g. suggesting directions for a
commonly traveled location (Tillman, 2019). Siri has also increased in supported
languages and dialects. For instance, as of early 2020, nine national English
variants are supported: Australia, Canada, India, Ireland, Nea Zealand,
Singapore, South Africa, UK, and US. Siri also has male and female voices
available.
These developments only respond in part to the scope of this project.
Of the 36 videos in my corpus (see Part 1 and References), three videos are
indeed aimed at national Englishes (two of Scottish users and one for Indian
users), and one video relates to a regional English (Hyderabadi users, from the
Indian state Hyderabad), while two videos pick at the range of Siri's supported
languages (Hawaiian Pidgeon English). Their complaints are addressed, at least
in principle, by Siri's developments. Other than those videos, however, all of
the accent videos examine having a non-native English accent (Korean, Chinese,
Vietnamese, French, Japanese, and Italian accents). In Part 2, this is particularly addressed.
Likewise, Siri's male and female voices say the same words for each, whereas
the parodies that deal with race, religion, sexual orientation, and sometimes accent/national origin identities
involve reimagining Siri's responses. Siri's personalization efforts may end up
capturing some of these identity aspects (such as going certain places), but unlike the parodies, today's
Siri never constrains those based on a person's identity. In Part 1, this is developed further.
As a technology, Siri is an example of the larger effort to process natural
language (natural language processing, NLP). NLP has been approached in many
ways over the decades (Jones, 2001) and today is usually accomplished, as in
Siri, by machine learning methods (Wikipedia Editors, 2020, "Speech
recognition"). Relevant here is the fact that supporting a new language/dialect
is time-intensive, often involving parallel corpora (Wikipedia editors, 2020,
"History of machine translation") that presuppose the background work of
multilingual writers and editors (Gonzalez, 2016).
It's hard to know someone's identity from watching them on a video, of course, so the statements made in this webtext should be read as tentative, with "(presumably)" as a silent qualifier for any identifier. By reimagining Siri to be more "like them," this includes identities that people resonated with rather than occupied themselves. Gabriel Iglesias, for instance, is a famed Mexican comedian, but in the bit analyzed here, he performs a black Siri. Similarly, the American comedian Robin Williams performs a French Siri, and in two parodies, a gay Siri is imagined for lesbians, and vice versa (a lesbian Siri for a gay guy). I suspect that in each of these, the historical interactions between these identities makes the political risks of adopting the other one minimal. A related resonance is when a (presumably) Hyderabadi teen (who is presumably not a woman-identifying parent himself) imagines interacting with Siri as a Hyderabadi mom.
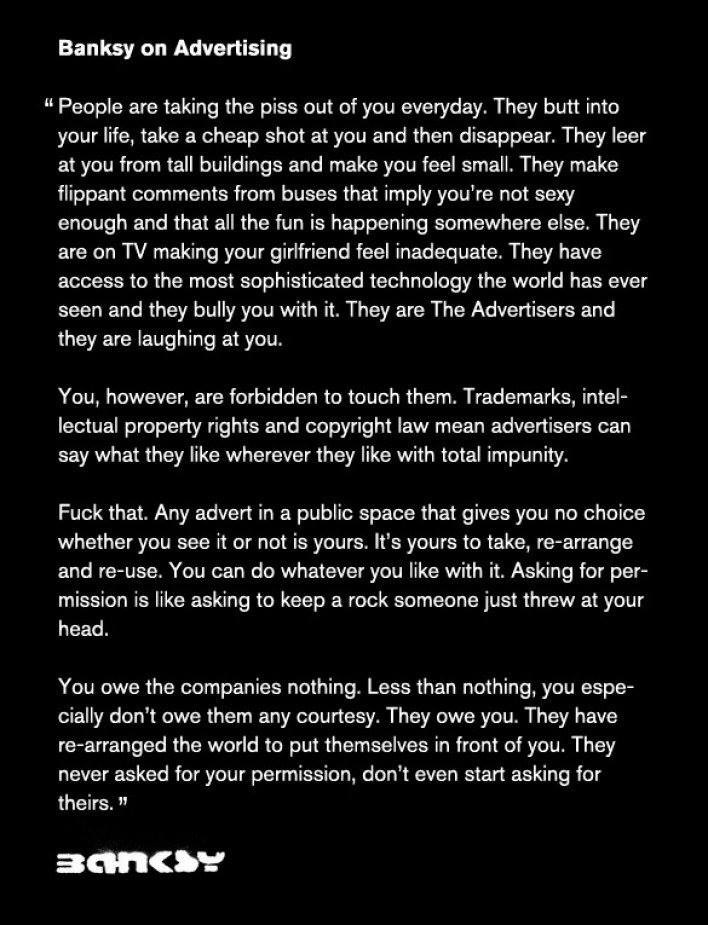
In three cases (Gabriel Iglesias' bit; a set of 10 segments from a Japanese TV series uploaded as "Funny When Japanese Try To Speak English With Siri! So Hilarious!"; and a clip of Robin Williams on Ellen), the YouTube uploader is not one of the people responsible for making the video (again presumably, based on the account names). This creates instability for those three videos on YouTube due to copyright claims. In fact, the "Funny When" series has already been removed once and been reuploaded under the same title by other accounts. I refer to "YouTubers" then with this in mind. Despite this legal fragility, I’ve quoted them equally in this paper. This is partly to acknowledge the other parodies as doing equal discursive work; it’s also partly to push back against the power that corporations hold on our reuse. For more on this, see Banks (2011) on remixing, the code of best practices in fair use for scholarly research by the ICA (Jaszi & Aufderheide 2010);
and a quote attributed to Banksy:
Research questions
In Part 1, we’ll explore how the parodies make a positive argument for
developing identity-specific AI (like a black Siri, or a gay Siri). This
contributes to scholarly work on how people respond to being represented technologically.
The positive argument is that AI can participate in developing people’s
identities that matter to them and create points of connection with others. For
people in dominant social positions, Part 1 challenges us to be generous
listeners, allowing the videos’ jokes to unsettle us and revise what we think is
possible; for people who have historically been unheard, I hope this part of the
project helps reconceptualize how AI development could proceed more
inclusively.
After this positive argument (or before, if you want to watch it now), Part 2
is devoted to how the videos make a negative argument, that there are losses
from today’s bland, universalizing AI. The parodies uncover that today’s AI
is developed to erase people's identities, and the parodies implicitly extend
scholarship that critiques identity erasure: namely, these parodies
argue that today’s Siri reproduces a dominant mode of operation, part of which
is to cover over the fact that it’s already a social agent – for better or for
worse, it already participates in people’s identity construction. For people of
minority identities, Part 2 is meant to amplify existing critiques of identity
erasure and apply those more visibly into voice-driven AI; for people in
dominant social positions, Part 2 is a chance to take our ongoing work of
renouncing oppression and its fruits and extend that into artificial
intelligence. In other words, we need to divest from racial, sexual, national,
and religious privileges as they manifest in AI, too.
Commentary and points of connection for "Research questions"

Siri's abilities have expanded over time. Since 2016, Siri has been able to serve as an interface for other apps, and this has been extended to allow custom commands and bundled actions (Tillman, 2019). Users can now correct Siri's pronunciation of individual words (Mundy, 2019), and Siri personalizes recommendations based on a users' habits, e.g. suggesting directions for a commonly traveled location (Tillman, 2019). Siri has also increased in supported languages and dialects. For instance, as of early 2020, nine national English variants are supported: Australia, Canada, India, Ireland, Nea Zealand, Singapore, South Africa, UK, and US. Siri also has male and female voices available.
These developments only respond in part to the scope of this project.
Of the 36 videos in my corpus (see Part 1 and References), three videos are indeed aimed at national Englishes (two of Scottish users and one for Indian users), and one video relates to a regional English (Hyderabadi users, from the Indian state Hyderabad), while two videos pick at the range of Siri's supported languages (Hawaiian Pidgeon English). Their complaints are addressed, at least in principle, by Siri's developments. Other than those videos, however, all of the accent videos examine having a non-native English accent (Korean, Chinese, Vietnamese, French, Japanese, and Italian accents). In Part 2, this is particularly addressed.
Likewise, Siri's male and female voices say the same words for each, whereas the parodies that deal with race, religion, sexual orientation, and sometimes accent/national origin identities involve reimagining Siri's responses. Siri's personalization efforts may end up capturing some of these identity aspects (such as going certain places), but unlike the parodies, today's Siri never constrains those based on a person's identity. In Part 1, this is developed further.
As a technology, Siri is an example of the larger effort to process natural language (natural language processing, NLP). NLP has been approached in many ways over the decades (Jones, 2001) and today is usually accomplished, as in Siri, by machine learning methods (Wikipedia Editors, 2020, "Speech recognition"). Relevant here is the fact that supporting a new language/dialect is time-intensive, often involving parallel corpora (Wikipedia editors, 2020, "History of machine translation") that presuppose the background work of multilingual writers and editors (Gonzalez, 2016).